In this tutorial we are going to learn about information bottleneck (IB) and the setting in which it is defined. then I will introduce to you a new setting “Multi-View Unsupervised Learning” and we are going to learn how IB can be extended to this setting. this tutorial is based on Learning Robust Representations via Multi-View Information Bottleneck.
Information Bottleneck
Consider the standard supervised learning setting; we have an input RV
Information Bottleneck Setting
given two RVs
and , find a representation for (called ) such that is minimally sufficient for .
In our formulation we paraphrased the two conditions we enumerated into “minimally sufficient”. we now elaborate on this:
Sufficiency
consider the following Markov chain
; is sufficient for if .
by applying Data Processing Inequality (DPI) on both Markov chains we get:
Therefore sufficiency leads to
More on Sufficiency
Actually
Thus
Minimal Sufficiency
A sufficient statistic (
) is a minimal sufficient statistic, if it is a function of every other sufficient statistic . or equivalently forms a Markov chain.
Again by applying DPI we get:
so minimal sufficient statistic is the one having the lowest
A Note on Minimality
in our discussion so far we have explained the pursuit of minimality based on model complexity and data efficiency. we now give another reasoning based on out of distribution generalization and robustness followed by an example:
the more a representation is independent of
Cats and Dogs 😺🐶
consider a dog vs cat classification task where we are given an input image
cats are more likely to be photographed in indoor environments while dogs are more likely to be photographed in outdoor environments.
but this property is reversed in test distribution. Now consider two models:
uses both information of background and object shape to determine the label. only relies in object shape. both these models are going to perform well in training data but it is obvious that is going to perform better in testing data. what separates from ? dependence on is less than .
Optimization
Knowing more about minimal sufficient statistics we can write the IB objective as:
assuming a parametric family of conditional distributions
where
-
Let’s write
as following: Thus
and putting this in IB Lagrangian objective we get: -
Assume
and are both MSS. Now based on the definition of MSS must be a function of and vise versa. Hence: fixing , minimizing is equivalent to maximizing . Additionally following proposition 2.1 of Achille17 can be written as where . so for to be a function of means that cannot depend on and so . Now we can write another objective for optimizing a parametric representation based on IB: and it’s Lagrangian is:
we can view
is the “informative” part of and as “superfluous” part and thus IB tries to increase dependence of on and decrease it’s dependence on .
Multi View Setting
In IB a principal assumption is that we have a dataset of labeled inputs; however labelling large amounts of data is costly and time-consuming. So in practice we cannot have large labeled datasets. Instead what we have are large unlabeled datasets. There are two scenarios that are of interest to us in such settings:
-
multi-view: our observations are compromised of multiple views. for example we might be interested in classifying a 3D object based on a 2D image of it and we are provided with multiple images of each object taken from different angles. or we want to tag a social media post and we are provided with it’s image and author’s short description. The underlying assumption in this scenario is that down-stream tasks we are interested in are invariant to the views. to make this more formal we define
to be the original object of interest, to be a view of and a property of interest. then: -
self-supervised: we do not have access to multiple views of
but we are aware of some invariances of label w.r.t input in the form of a set of transformations . meaning that we can create our views by applying transformations present in to our observations.
Multi-View IB
Now a natural question is how one can extend the IB framework into Multi-view setting?
Method
Building Intuition
IB tries to find a representation that while is faithful (sufficient) tries to maximally discard information present in
We define redundancy to formalize the assumption that all views have the same predictive information regarding
Redundancy
We say
is redundant with respect to for if . Also we say and are mutually redundant if .
The following Corollary formalizes our intuition that variant parts of views can be discarded for prediction of
Corollary
Let
and be two mutually redundant views for a target and let be a representation of . If is sufficient for then is as predictive for as the joint observation of the two views.
based on this Corollary we can now extend IB to the multi-view setting. i.e. a good representation in this setting is the representation found by IB in the supervised task of predicting
How should views be?
The more two views are different the more they are informative of what information can be discarded and hence the more we lower
. at the extreme the only shared information between views would be the label information and we show that our method reduces to traditional IB.
Now we are in a place to define the optimization objective of Multi-View IB; based on the above ideas we need to focus on
where
averaging the two losses:
this can be upper bounded by the following loss:
where
Intuitively this loss encourages
The symmetric KL can be computed directly when
Below we have presented the optimization algorithm corresponding to this objective accompanied by an schematic describing the algorithm visually:
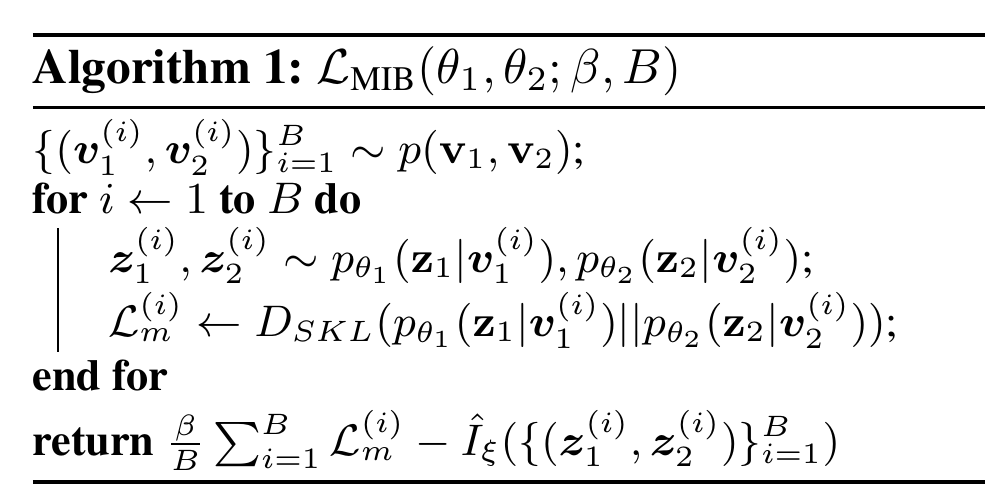
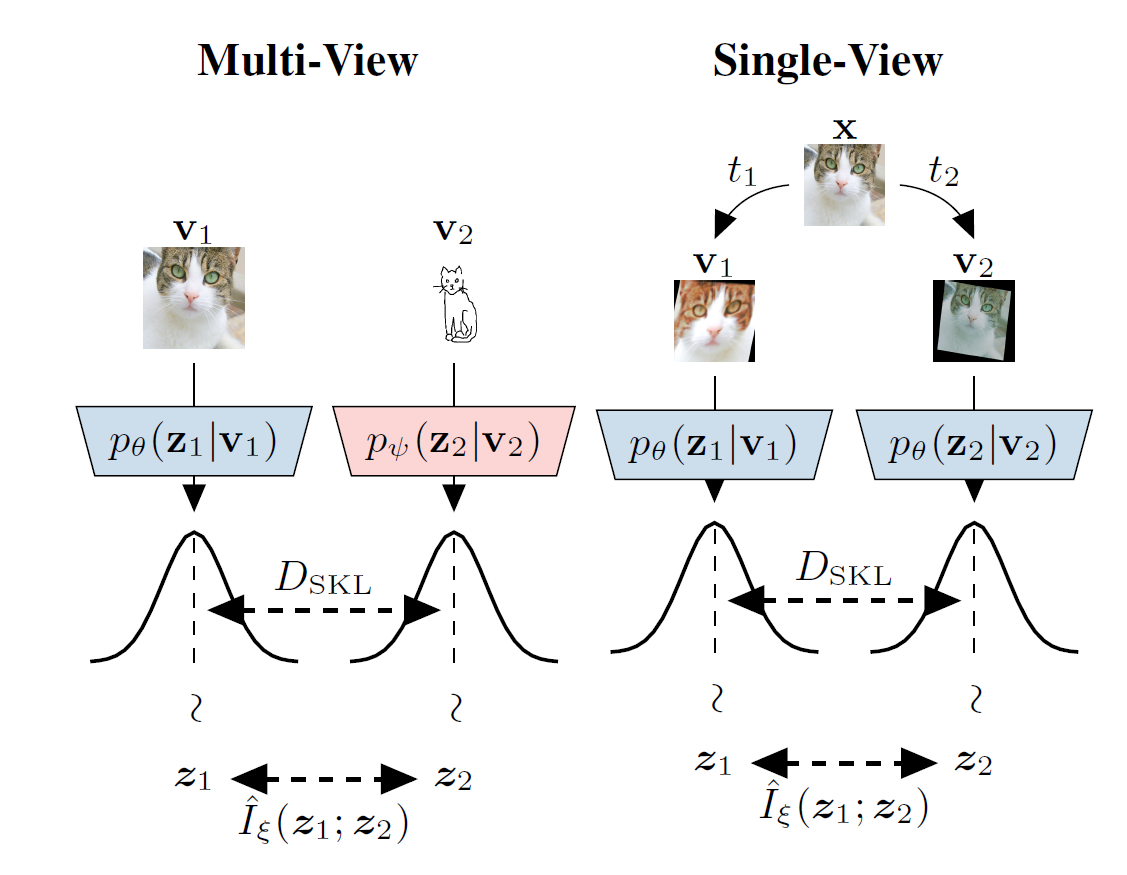
A Note on Single View Setting:
what can we do when we do not have access to multiple views? a simple solution is to come up with a set of transformations on data that we believe down-stream tasks would be invariant to. (e.g. rotation of input image in dog/cat classification example). then we create the required multi-view dataset of our setup as follows:
- sample transformations
and randomly and independently from set of transformations . - set
and . if our assumption about these transformations is true:
and thus these two views are mutually redundant with respect to
Related Work
we employ the information plane to create a holistic view of this method and its relation to other methods of representation learning in multi-view setting.
information plane is a 2D figure where axis represent
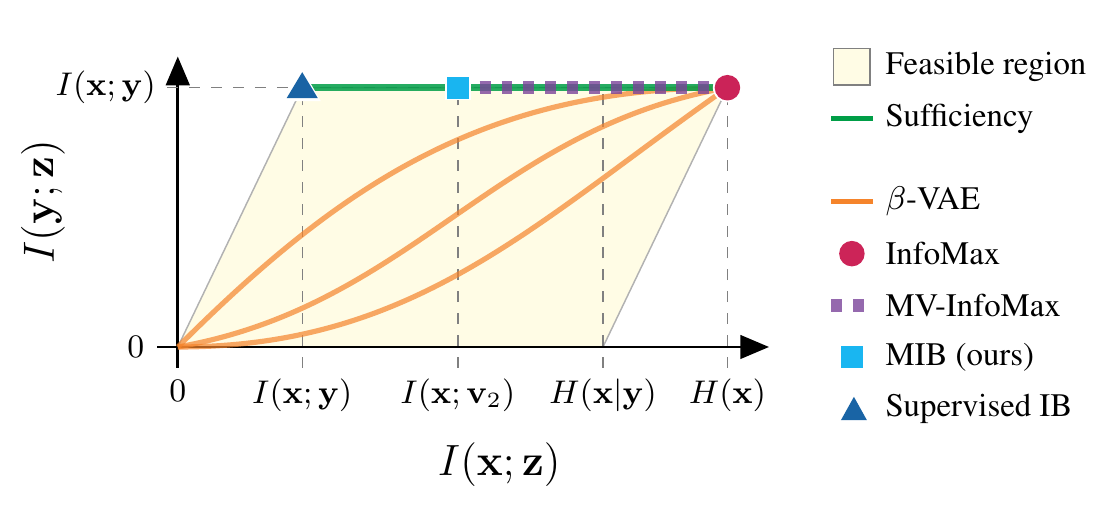
-
Supervised IB: given label
optimizing IB objective leads us to the top left corner of the plane. this representation has best predictive performance and is most generalizable. -
Infomax: based on this method good representations should have maximal mutual information with input (right most corner).
trivially satisfies this objective; to prevent this, different methods employ different architectural constraints on . -
MV-Infomax: these methods are extensions of the Infomax Idea and they try to maximize
which can be proved to be a lower bound on . by maximizing they maintain the sufficiency property but don’t put any restrictions on which leads to representations having different values of ranging from MIB to Infomax. -
-VAE: this method finds a latent representation that balances compression and informativeness by a hyperparameter . the main disadvantage of this method is that informativeness is measured by and thus when we increase , becomes more compressed while trying to maintain but there is no explicit preference to which information about should be discarded to accomplish the compression of and this preference is implicit in the choice of architecture. this means architectural choices can be made such that compression leads to maintaining sufficiency for (higher curves in the figure ) or on the other hand opposite of this; such that compression leads to discarding predominantly information pertinent to prediction of (lower curves in the figure). -
MIB: our work has the advantage of discarding information like
-VAE, but explicitly forces to maintain sufficiency like Infomax objectives. this leads to discarding of only irrelevant information for predicting .
Experiments (Multi View)
Sketch-Based Image Retrieval
Dataset. The Sketchy dataset consists of 12,500 images and 75,471 hand-drawn sketches of objects from 125 classes. we also include another 60,502 images from the ImageNet from the same classes, which results in total 73,002 natural object images.
Setup.
The sketch-based image retrieval task is a ranking of natural images according to the query sketch. Retrieval is done for our model by generating representations for the query sketch as well as all natural images, and ranking the image by the Euclidean distance of their representation from the sketch representation. The baselines use various domain specific ranking methodologies. Model performance is computed based on the class of the ranked pictures corresponding to the query sketch. The training set consists of pairs of image
we use features extracted from images and sketches by a VGG architecture trained for classification on the TU-Berlin dataset. The resulting flattened 4096-dimensional feature vectors are fed to our image and sketch encoders to produce a 64-dimensional representation.

MIR-Flickr
Dataset.
The MIR-Flickr dataset consists of 1M images annotated with 800K distinct user tags.
Each image is represented by a vector of 3,857 hand-crafted image features (
Setup. we train our model on the unlabeled pairs of images and tags. Then a multi-label logistic classifier is trained from the representation of 10K labeled train images to the corresponding macro-categories. The quality of the representation is assessed based on the performance of the trained logistic classifier on the labeled test set.
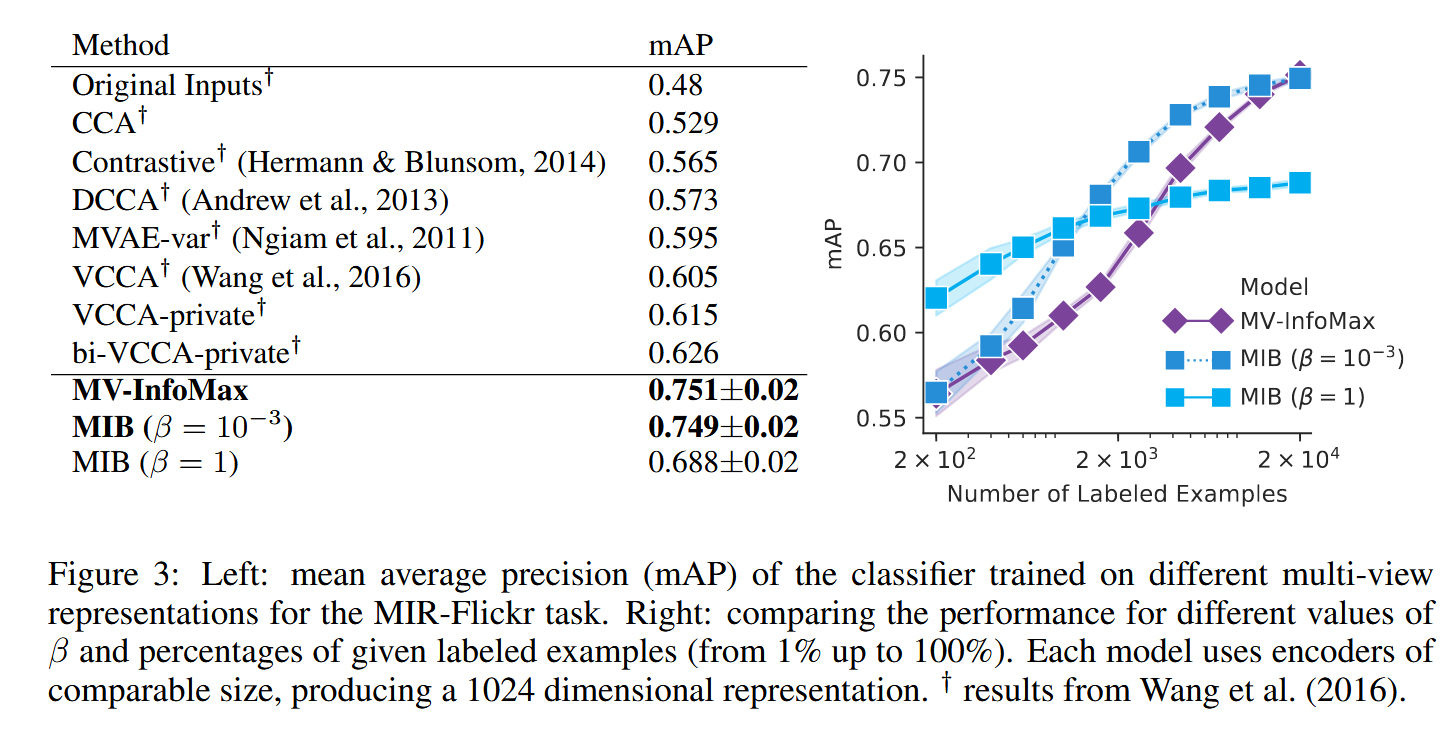
Results.
Our MIB model is compared with other popular multi-view learning models in the above Figure. Although the tuned MIB performs similarly to Multi-View InfoMax with a large number of labels, it outperforms it when fewer labels are available. Furthermore, by choosing a larger
A possible reason for the effectiveness of MIB against some of the other baselines may be its ability to use mutual information estimators that do not require reconstruction. Both Multi-View VAE (MVAE) and Deep Variational CCA (VCCA) rely on a reconstruction term to capture cross-modal information, which can introduce bias that decreases performance.
Experiments (Single View)
In this section, we compare the performance of different unsupervised learning models by measuring their data efficiency and empirically estimating the coordinates of their representation on the Information Plane.
Dataset.
The dataset is generated from MNIST by creating the two views,
Setup.
To evaluate, we train the encoders using the unlabeled multi-view dataset just described, and then fix the representation model. A logistic regression model is trained using the resulting representations along with a subset of labels for the training set, and we report the accuracy of this model on a disjoint test set as is standard for the unsupervised representation learning literature. We estimate
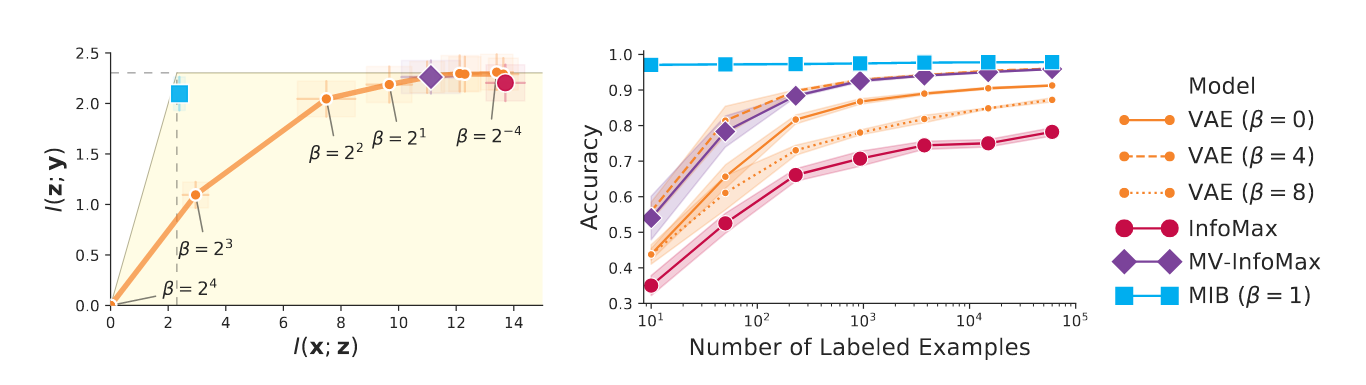
Results.
The empirical measurements of mutual information reported on the Information Plane are consistent with the theoretical analysis reported in Related word section; models that retain less information about the data while maintaining the maximal amount of predictive information, result in better classification performance at low-label regimes, confirming the hypothesis that discarding irrelevant information yields robustness and more data-efficient representations.
Notably, the MIB model with
Future Work
-
MIB is only applicable to two-view settings and so a prominent future work direction is to extend this idea to multi-view settings with no limit on number of views.
-
an important drawback of Information Bottleneck is that it’s invariant to one-to-one transformations and thus does not put any constraints on the distribution of learned representation or whether is should be disentangled or not. while other forms of representation learning like VAEs, Normalizing Flows, etc… explicitly regularize representations to admit to a simple prior distribution. I think a promising area of research is combining IB ideas with VAEs in Multi-view setting.